Bestaro goes Serverless with Pulumi - Part I
18 March 2020
A good few months ago I've finished the work on project Bestaro - the software project used by Mapa Zwierzat. In short, it's meant to fetch annoucements about lost and found pets from Facebook and similar pages and then, after extracting the location, present them on a map. I still didn't manage to get access to Facebook data of any animals group in Poland, but in the mean time I'e decided to decrease the cost of the infrastructure and make it easier to manage.
The most pressing issue regarding the costs was the frontend server. Because of expected high volume of animal images, I had to provision a VPS with a big HDD, which was not being used at the moment and, if all the space were used one day, would require a painful migration. Images had also to be stored locally in the Backend until they are sent to Frontend, which led to unnecessary duplication. But even if images were stored in a better place, I had to run a resource-consuming PostgreSQL database server with PostGIS extension to be able to efficiently query for the recent events in the specific geographic area. Not to say I had very hard time working with Play Framework and Scala's SBT package manager. Number of situations when I didn't know why something was not working, where to look for documentation and multiple inconsistencies made me think I never want to use it again.
Going serverless
At work I've been extensively using Terraform for a few months, but I've decided to stick to Pulumi with which I've experimented on my own (I've mentioned it when Building Pelican Blog in AWS Lambda). The main advantage is using real language (I use JS) instead of a custom markup language. I also feel like it's easier to fix the problems which arise when provisioned infrastructure becomes desynchronized from framework's internal state.
The old design
First of all, I had to investigate the current solution and decide how to redesign it. I've decided to leave backend unchanged and focus on frontend. Backend part will be reworked in Part II of this post.
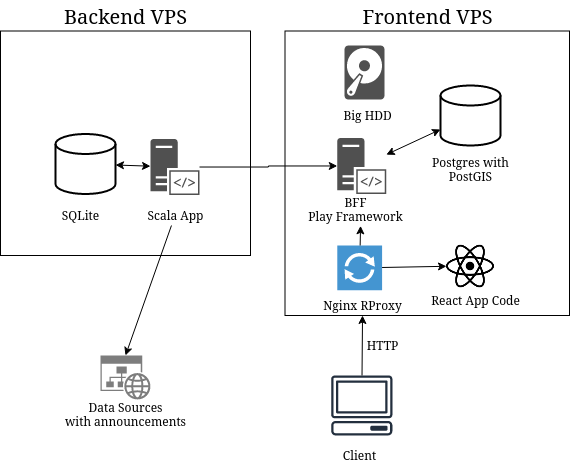
Backend consisted of the collowing components:
- Standard Scala App that collected and processed the announcements from multiple sources
- SQLite for storing the processed results
- Space on local filesystem for storing images before they are sent to Frontend
And Frontend:
- Backend-for-Frontend in Play Framework using Scala
- Postgres + PostGIS database for storing and efficiently querying for the records for a specific area and timeframe
- Space on local filesystem for storing images
- Single Page App in React that displays the map
- Nginx Reverse Proxy that serves React Frontend and API over the same domain (to avoid problems with CORS)
So the old architecture looked like that:
The new design
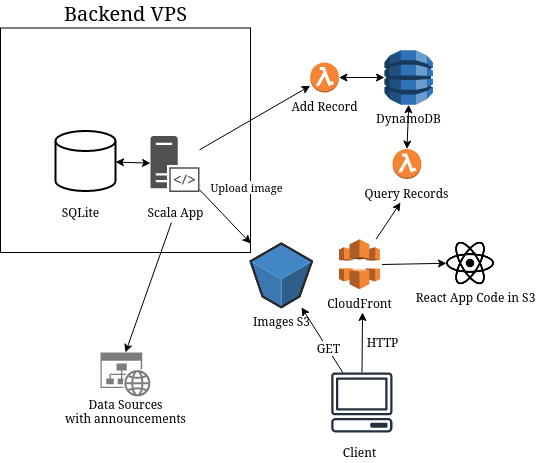
In the new design there's no clear distinction between Backend and Frontend in their previous meaning. As Backend I consider the things I've not changed in Part I, so it's:
- Standard Scala App that collected and processed the announcements from multiple sources
- SQLite for storing the processed results
The serverless part of the system has the following components:
- S3 bucket for animal images, which are sent by Backend App and fetched directly by client's browser
- DynamoDB for storing information about records
- Two Lambda Functions for adding and querying for the records, both behind API Gateway
- Single Page App in React that displays the map, stored in S3 bucket
- CloudFront Distribution that works as a reverse proxy, directing traffic to S3 with React App or to Query Records Lambda
The new architecture is presented on the diagram:
It has several advantages: images are stored in a single place, moreover I don't need a web server working indefinitely to serve data from the API. It's not necessary to have a VPS for Frontend, because S3, CloudFront, Lambda and DynamoDB are serverless services.
I'll shortly explain what the specific parts of the system do and how do I provision them.
Images in S3
The first thing was creating the bucket for images and making a small adjustment for the Backend Scala App - it should upload files to this bucket using AWS SDK.
Infrastructure in Pulumi:
const imagesBucket = new aws.s3.Bucket(`bestaro-images-${stackName}`, {
acl: 'public-read',
corsRules: [{
allowedHeaders: ['*'],
allowedMethods: [
'GET',
],
allowedOrigins: ['*'],
exposeHeaders: ['ETag'],
maxAgeSeconds: 3000,
}],
});
const backendUser = new aws.iam.User(`bestaro-backend-user-${stackName}`);
const backendUserAccessKey = new aws.iam.AccessKey('bestaro-backend-access-key', {
user: backendUser,
});
exports.backendUserAccessKeyId = backendUserAccessKey.id;
exports.backendUserSecretAccessKey = backendUserAccessKey.secret;
As you can see above, the bucket is created with CORS rules so the images are publicly available and can be loaded by the client browser from any domain. And because the backend is run outside of AWS, I had to create an IAM user and access key which can be used by the Backend App to authenticate to AWS and upload the files (IAM policies for uploading data to S3 omitted for brevity).
Scala code for uploading the image:
private val awsCredentials = new BasicAWSCredentials(
properties.getProperty("accessKeyId"),
properties.getProperty("secretAccessKey"))
private val bucketName = properties.getProperty("imagesBucketName")
private val instance = AmazonS3Client
.builder()
.withCredentials(new AWSStaticCredentialsProvider(awsCredentials))
.build()
def uploadImage(name: String, content: File): Unit = {
instance.putObject(bucketName, "pictures/" + name, content)
Servi1g static website from S3
If you've read my previous post about serverless) I've linked before, you know I've already created a static website using S3, but with Serverless Framework.
It didn't take me much time, I just copy-pasted the code from Pulumi examples and converted it from TS to JS. It provisions S3, Access Policies, CloudFront, Domain Record, Certificate. It also uploads the website's files as part of the state tracked by Pulumi. I think it's not necessary to put additional explanation, as the linked code is well documented. For now I have to build the React App locally and then upload the files from the ./build directory.
DynamoDB
Use of this component was the biggest challenge, because in the serverful solution PostGIS gave access to refined geographical data types, while DynamoDB allows using just two indices (called hash (partition) key and sort key) of which the first can be queried just for strict equality and the other can use simple math or string operations. The ways of accessing the data need to be designed at the moment of table creation. It's impossible to pack two floats in the sort key to find only points in a specified rectangle to get points fitting the visible area of the map. The solution for this problem was to use Geohash, which makes it possible to represent geographical position as a single string, of which each consecutive character gives a more precise information about position. As hash key I've used year and month of the event - it doesn't serve as an ideal parition key, but it gives rough filtering.
I'll describe the details of my solution in the next post.
Lambdas for adding and querying the records in DynamoDB
AWS Lambda is a service that allows running arbitrary code in one of a few supported languages without caring about infrastructure on which it is run. It has some limitations and is not suited for complex applications, but it's a good choice for my use case. Of course, it's possible to make external processes directly run queries against a publicly accessible DynamoDB instance, but I think it's worth having a centralized place to validate data and design the queries so they are well optimized. It's a safe choice especially considering 1 million of Lambda invocations per month are free. The details of inserting and querying will be explained together with DynamoDB structure, but here's a snippet of how easy it was for me to create Lambdas behind an API Gateway:
const endpoint = new awsx.apigateway.API('bestaro-frontend-api', {
routes: [
{
path: '/api/upload',
method: 'POST',
eventHandler: async (req, ctx) => {
const record = getJsonBody(req);
await functions.addRecord(record, table.name.get());
return {
statusCode: 200,
body: JSON.stringify({ ok: true }),
headers: { 'content-type': 'application/json' },
};
},
},
... the other function here
]
});
It could be further polished, but even now it looks pretty straightforward IMO.
Single Page App in React stored in S3 bucket
Not many changes here. It's a JS app bootstrapped using Create React App. The only difference is that it's built locally and then uploaded to S3. I've chosen the simplest solution - to store the files as part of Pulumi state. I'd avoid adding so fragile objects to the state in Terraform, for example, but Pulumi handles discrepancies between stored state and reality pretty well. You just need to run pulumi refresh and it usually updates it accordingly.
I build the project locally using npm run build and then run pulumi up so the contents of the directory are uploaded.
CloudFront Distribution
Reverse proxy - an invisible, but very important part of the system. It's supposed to do the same stuff as Nginx did. Requests to path https://mapazwierzat.pl/api/* should be routed to API Gateway (and Lambdas), while all the others should direct to S3 with React App. It's also necessary to take care of HTTPS certificates. The fact AWS takes care of certificate renewal is an added benefit, because in my old solution I had some issues with renewing the LetsEncrypt certificates and often had to do it manually.
I won't paste the code, because it's very long. I've basically copied the configuration of CFD from the official example I've mentioned earlier.
The only thing I had to do was to add routing for path /api/*. Again, I didn't have to invent anything on my own and I've just ported the solution presented in a wonderful blog post How to route to multiple origins with CloudFront. It's a tutorial for Terraform, but fortunately many Pulumi libraries are just a wrapper around Terraform, so the parameters of the resources correspond 1-1. I had to transform the code snippet in the "2) API Gateway origin" paragraph in the article above. The part I had to add to CloudFrontDistribution for correct routing of API. The resulting code
origins: [
{
domainName: apiGateway.url.apply(s =>
s.replace(/^https?:\/\/([^/]*).*/, '$1')),
originId: 'api',
originPath: '/stage',
customOriginConfig: {
originProtocolPolicy: 'https-only',
httpPort: 80,
httpsPort: 443,
originSslProtocols: ['TLSv1.2'],
}
}
],
orderedCacheBehaviors: [
{
pathPattern: '/api/*',
allowedMethods: ['DELETE', 'GET', 'HEAD', 'OPTIONS',
'PATCH', 'POST', 'PUT'],
cachedMethods: ['HEAD', 'GET', 'OPTIONS'],
targetOriginId: 'api',
defaultTtl: 0,
minTtl: 0,
maxTtl: 0,
forwardedValues: {
queryString: true,
cookies: {
forward: 'all',
},
},
viewerProtocolPolicy: 'redirect-to-https',
},
],
The interesting thing is you can't make orderedCacheBehaviors[].cachedMethods empty, but you can set it as above but with cache TTL set to 0, which virtually disables the cache.
Unfortunately, the configuration above, despite being defined in JavaScript, looks like a typical infrastructure markup like YAML/JSON. The benefit of the real language is ability to easily convert paramters in the way you like. And even better thing is, you don't really need to copy-paste this solution and adjust according to your needs, because I've extracted it as a Pulumi Component available on npm.
Then, assuming you create a bucket for website and API Gateway with Lambdas, usage is as follows:
const { StaticFrontendWithLambdaBackend } = require('pulumi-s3-lambda-webstack');
const apiGateway = new awsx.apigateway.API('bestaro-frontend-api', {...});
const contentBucket = new aws.s3.Bucket('bestaro-front', {...});
const frontendWithBackend = new StaticFrontendWithLambdaBackend(
'bestaro', domainName, siteBucket, apiGateway);
I think it's hard to make it more concise.
The code for StaticFrontendWithLambdaBackend component in version 1.0.1: https://github.com/alchrabas/pulumi-s3-lambda-webstack/tree/1.0.1
The code for my infrastructure (at the moment of writing the post): https://github.com/alchrabas/bestaro/blob/0.0.1/aws/index.js
Summary
I hope the ease with which I've created this service will encourage you to give Pulumi a try. Not all things are possible, but the things that are supported, work pretty reliable and usually don't require a lot of code. The main issue I have with Pulumi, when compared to Terraform, is the lack of null_resources, which can be used to execute bash scripts at certain stages of deployment. Being able to run lifecycle callbacks would help a lot, but it's still reported as 'being worked on' for a long time.
My Pulumi Component might still be improved, for example it doesn't take different stages (dev, prod) into account, but I consider it a good starting point and it can be expanded in the future if needed.
In the next post I plan to explain how do I use DynamoDB for spatial search and how it is different from the already available solutions I found in the internet. Then, in Part II of this post, I will run Scala Backend on AWS.