Building Pelican Blog in Lambda
21 July 2019
As you probably know when reading it, I have a blog. It's a static website generated by Pelican - a static site generator written in Python. It's taking posts written in Markdown and rendering HTML content out of it. This makes the source code suitable to be stored on Github, which is available here. The most typical way of using Pelican is to make changes in Markdown locally and then also locally run a python script to create output/ directory that needs to be put on some hosting. I didn't want to have access to the hosting site from any location on which I worked on my blog, I also didn't want to use the simplest solution, that is to serve it on GitHub Pages, so I've prepared a hand-crafted solution, that automatically builds & hosts this on one of my servers.
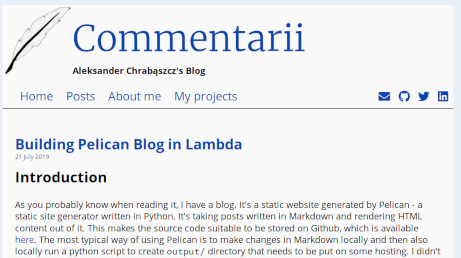
That's how my blog looks like
The flow I've managed to set up was like that:
- When something is pushed to master branch, then call a webhook
- The GitHub's webhook calls an endpoint on my VPS, where apache runs a PHP script
- This PHP script runs bash script that makes
git pulland rebuilds pelican blog tooutput/directory output/directory is served by apache as static files
It was working very well, so I decided to redo it in another technology ;) I've decided to do it in serverless, both to experiment and to reduce cost. I hope to shot off some of my VPS, because I use them a little and they still generate cost.
I've decided to use AWS Lambda. It may sound a little strange, because Lambda is generally not the best thing to handle IO-intensive apps and creating a simple docker image to serve the same purpose would take me 20 seconds, but, as I've said, I'd like to start playing around with Lambda by creating code that does some real work. I'm sure the experience will be helpful in the future.
Framework selection
My first bet was Pulumi, as it's a really new framework that sounds like a dream for a developer - real Infrastructure as Code. When I want to create an EC2, I just need to write:
// declaration of security group omitted for brevity
let server = new aws.ec2.Instance("my-ec2", {
instanceType: "t2.micro",
securityGroups: [ group.name ],
ami: "ami-7172b611"
});
Or, when I want to create an S3 bucket with a Lambda run for each new object, it's enough to write something like that:
let bucket = new aws.s3.Bucket("mybucket");
bucket.onObjectCreated("onObject", async (ev) => {
// some code here
});
In fact, these two are just excerpts from documentation of Pulumi, so I encourage to go there and take a look. For Lambdas there are special wrappers for AWS SDK to access external resources to make them easier to use. It works, because JS Lambda code is converted into its final form by Pulumi before it's pushed to AWS.
Pulumi is very well documented, but... at least now (beginning of 2019) only for JS/TS. It appears that Python has different API from JS and, at the same time, it's pretty hard to combine Infrastructure definition in JS with Lambda code in Python. There's a nice example here of how to make Lambdas in many languages while using JS for infrastructure, but I found it not friendly and it wasn't obvious for me how to build a Python Lambda with dependencies.
That's why I've decided to use Serverless Framework, which uses less friendly YAML for infrastructure, but is more stable and has good documentation.
Start coding Lambda in Serverless Framework
The repository with the working code for site chrabasz.cz in region eu-central-1 is available here.
The first thing I needed to do in Lambda was to clone my repository. It's a pretty small private blog, but it uses a custom theme as a submodule, so it's not the simplest setup.
The first surprise (maybe not that big) was the fact there's no Git in lambda. Fortunately there exists a python library called lambda-git that contains a bundled git and provides programmatic access to it through Python.
So I was happy to put the following code line hoping it will just work:
stdout, stderr = git.exec_command('clone',
"git@github.com:alchrabas/blog.git", "/tmp/blog", cwd="/tmp")
But it didn't work, because it's not easy to configure SSH access in lambda. So I've decided to try the easier solution: clone the repo by https. There's no authorization needed, because the repository is public.
stdout, stderr = git.exec_command('clone',
"https://github.com/alchrabas/blog.git", "/tmp/blog", cwd="/tmp")
Ok, that worked better. The important thing to know is that lambda's default directory is /tmp/. That's why I've put this as cwd and the blog directory a subfolder of it.
Another small problem arose regarding the submodules. It looks like the git bundled in the library runs some perl code and Perl is unfortunately unavailable in Python Lambda:
Git stdout: , stderr: Cloning into '/tmp/blog'...
/tmp/usr/libexec/git-core/git-submodule: line 168: /usr/bin/perl: No such file or directory
So I had two choices. Either try to completely change the way the code is cloned to the Lambda's filesystem (e.g. use Perl Lambda, look for some AWS service that suports Git OOTB) or just clone the submodule manually. I went with the second approach.
stdout, stderr = git.exec_command('clone', "https://github.com/alchrabas/crowsfoot.git",
"/tmp/blog/crowsfoot", cwd="/tmp/blog")
Two lines more and problem solved :D
Also, because the warmed up lambda is reusing the same filesystem if it's run again, I've added the code to remove /tmp/blog in case it already exists:
if os.path.isdir("/tmp/blog"):
shutil.rmtree("/tmp/blog")
Maybe it would be more efficient to just update the repo if it already exists, but that would be a microoptimization that doesn't give much, but requires more testing.
Running pelican
The next thing I had to do was to run the Pelican to compile the blog into a set of static files that could be put on S3. Usually people use Makefile with CLI scripts that somehow run the Python. I hoped that running it programmatically will be a popular way of doing it and also explained in documentation, but it wasn't. After some time of searching and reading Pelican's code I've stumbled upon an issue "Is there a way to generate a site programmatically?" on Pelican's GitHub.
That part was exactly what I needed:
os.chdir(blog_dir)
settings = read_settings("publishconf.py")
pelican = Pelican(settings)
pelican.run()
Serve static web site from S3
With the current setup I was able to get a compiled version of a blog in /tmp/blog/output directory inside of lambda function. Another step was to copy the files to S3 using the following helper function (assuming path = /tmp/blog/output/ and bucket_name is the name of a bucket provisioned by serverless framework):
for root, dirs, files in os.walk(path):
for filename in files:
local_path = os.path.join(root, filename)
relative_path = os.path.relpath(local_path, path)
s3.upload_file(local_path, bucket_name, relative_path)
I've done it and there came another problem - all files were uploaded with file type being binary/octet-stream (S3's default), so it was impossible to preview them in the browser.
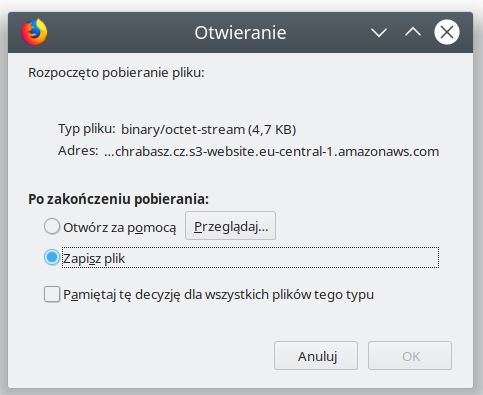
But this was easy to fix by adding an optional parameter to upload_file method:
s3.upload_file(local_path, bucket_name, relative_path,
ExtraArgs={
"ContentType": mimetypes.guess_type(filename, strict=False)[0] or "text/plain"
})
I've done so ContentType is guessed from the file's extension (luckily, mimetypes library is part of Python standard library).
Make bucket publicly available
It required some pretty standard (I hope) YAML code in serverless.yaml:
BlogBucketPolicy:
Type: AWS::S3::BucketPolicy
Properties:
Bucket:
Ref: BlogBucket
PolicyDocument:
Statement:
- Sid: PublicReadGetObject
Effect: Allow
Principal: "*"
Action:
- s3:GetObject
Resource:
Fn::Join: [
"", [
"arn:aws:s3:::",
{
"Ref": "BlogBucket"
},
"/*"
]
]
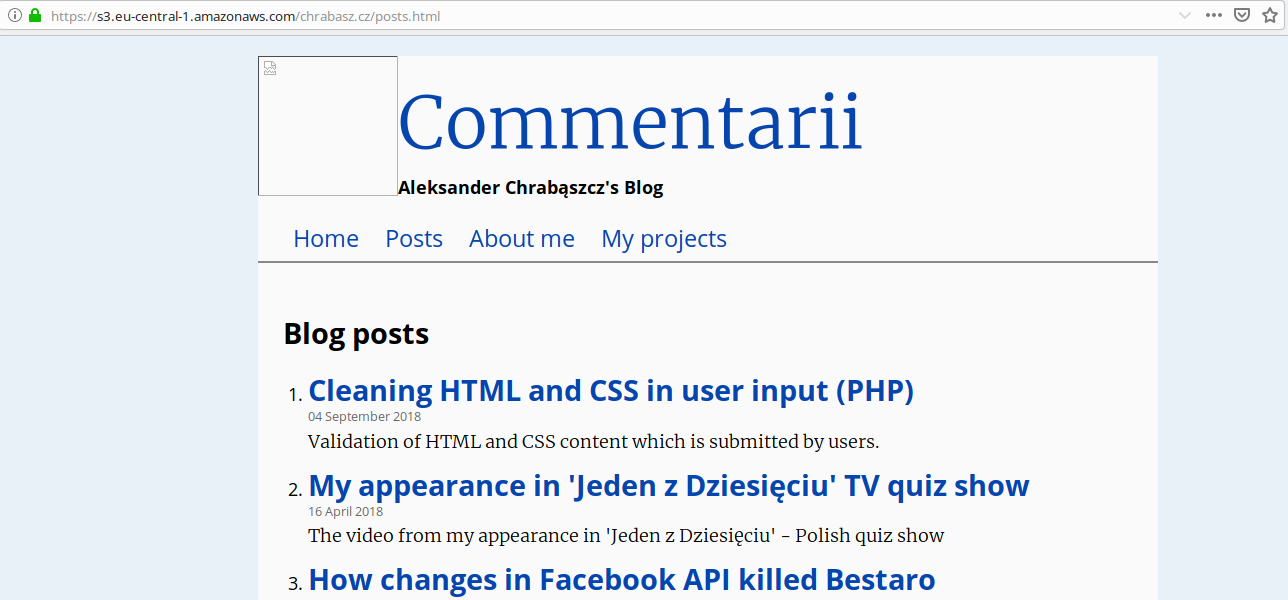
It became possible to see a single file, but references to the other resources (links, images) are not working
Add domain to Route53 to serve the static site from the bucket
This part was done manually, because it needs to be done once and with great care. I've changed NameServer of my domain hosted on OVH to point to AWS servers. I won't elaborate on that, because it's explained well in this article.
To create a record set automatically, I had to put the following piece of code in serverless.yml:
DnsRecord:
Type: "AWS::Route53::RecordSet"
Properties:
AliasTarget:
DNSName: "s3-website.eu-central-1.amazonaws.com"
HostedZoneId: Z21DNDUVLTQW6Q
HostedZoneName: ${self:custom.site_name}.
Name:
Ref: BlogBucket
Type: 'A'
DnsRecordWww:
Type: "AWS::Route53::RecordSet"
Properties:
AliasTarget:
DNSName: "s3-website.eu-central-1.amazonaws.com"
HostedZoneId: Z21DNDUVLTQW6Q
HostedZoneName: ${self:custom.site_name}.
Name:
Fn::Join: [
"", [
"www.",
{
"Ref": "BlogBucket"
},
]]
Type: 'A'
The small gotcha I've encountered are the values of DNSName and HostedZoneId. It needs to be the URL to the S3 bucket service in the specific region (without a part unique for your website - this part is handled by the bucket name). Also, to make it harder to configure automatically, you also need to set HostedZoneId, which I don't know how to obtain in code. I've taken these two values from the following table in AWS docs (it's necessary to pay attention to DNSName - for some regions there's a dash and for some there's a dot).
The last part was to change the URL fired in GitHub's webhook to the URL of Lambda in API Gateway.
Tada! When I enter http://chrabasz.cz I see the blog.
But there's one important thing missing in this solution - lack of HTTPS support. To make it work, it's necessary to use CloudFront and write another bunch of YAML.
Use CloudFront to enable HTTPS
There's not much to write about, just YAML:
CloudFrontDistribution:
Type: AWS::CloudFront::Distribution
Properties:
DistributionConfig:
Comment: CloudFront Distribution for a static blog in S3
DefaultCacheBehavior:
TargetOriginId: BlogOrigin
AllowedMethods:
- GET
- HEAD
ViewerProtocolPolicy: 'redirect-to-https'
DefaultTTL: 30
MaxTTL: 60
ForwardedValues:
QueryString: false
ViewerCertificate:
AcmCertificateArn: ${self:custom.acm_certificate_arn}
SslSupportMethod: sni-only
Enabled: true
Aliases:
- ${self:custom.site_name}
DefaultRootObject: index.html
Origins:
- Id: BlogOrigin
DomainName: ${self:custom.site_name}.s3.amazonaws.com
CustomOriginConfig:
HTTPPort: 80
HTTPSPort: 443
OriginProtocolPolicy: http-only
I'll explain the most interesting parts:
ViewerCertificate:
AcmCertificateArn: ${self:custom.acm_certificate_arn}
SslSupportMethod: sni-only
The above code contains a reference to an SSL certificate I've created manually for my domain. Global CloudFront certificates should be created in us-east-1 region. After it was done, I've copied ARN from the Web Console. It's a one-time job, so I'm ok with doing it manually.
Origins:
- Id: BlogOrigin
DomainName: ${self:custom.site_name}.s3.amazonaws.com
CustomOriginConfig:
HTTPPort: 80
HTTPSPort: 443
OriginProtocolPolicy: http-only
The code above specifies origin from which the files are served. In my case it's an S3 bucket. There are two ways to access the files: as objects in S3 or from a static website. I'm using a non-website URL. I have to do it using http because (I think) my bucket name contains a dot (chrabasz.cz) so the AWS' certificate *.s3.amazonwas.com doesn't work. But I'm not 100% sure whether it's the reason, as I didn't test it.
The last thing was to change AliasTarget, which earlier referenced website endpoint of S3 bucket and now it should lead to CloudFront:
AliasTarget:
DNSName: {Fn::GetAtt: [ CloudFrontDistribution, DomainName ]}
HostedZoneId: Z2FDTNDATAQYW2
HostedZoneId is an ID global for whole CloudFormation, so again I've copied it from the docs.
Summary
It was harder than I've evisioned, but I'm happy I've encountered and solved so many general problems regarding AWS. Regarding the use of Lambda - it would probably make more sense to use AWS Pipeline or something like that, because many things, like Git integration, would be handled OOTB. But I don't know if I'm ever going to need to use their Pipelines and I'm sure I'm going to use Lambdas.
As I've written in the beginning, the repository with the working code is available on GitHub.