Cleaning HTML and CSS in user input (PHP)
04 September 2018
Cantr, a browser-based role-playing game, is the first big programming project I've commited to.
The game is all about reading, so one of important features of the game is allowing people to create text notes, which then can be shared and read by other players. They have a few special features: allow people to post images (hosted on the game server) and add styles. In 2003, when the game and the notes feature were implemented, the easiest of available options was to allow players to use unrestricted HTML in notes.
That was a costly decision.
Problems with user input
In the beginning, when all the players were a group of friends, it was okay to not have any input validation. But soon it became clear it cannot stay that way. Allowing any HTML meant, obviously, that it's also possible to embed custom JavaScript. The first solution for that was introducing a blacklist of the dangerous tags, which was implemented pretty early. If you are into web security then you know that this solution was still easy to bypass. There are numerous ways to embed JS in attributes, for example, and a blacklist will never work. So security was the first huge issue.
The second problem was HTML posted by players without ill intentions, but invalid because of their lack of knowledge about HTML. For majority of players it was the first time in their life to use HTML. So problems like unclosed tags, use of <font> (blah) and so on were widespread, often leading to notes being rendered differently in different browsers.
The third problem was character encoding. If you remember the old times, when UTF-8 wasn't standard for web pages, then you can just imagine what happened when people of different languages were creating notes, each using their own character encoding. But that's an issue that was solved separately. Maybe I'll write something about it in the future, but majority of work was done before I joined the programming team.
Before I start writing about my solution, I'd like to voice that I see the drawbacks of allowing users to use HTML and, even more, forcing people to use it even if they have no prior knowledge of it. When developing a similar system now, I'd probably encourage people to use some simple formatting, like Markdown. In fact, in Exeris - the game I'm developing - the concept similar to notes will be supported mostly by Markdown. But 15 years ago Markdown didn't exist and when I've started to tackle the problem, there were already hundreds of thousands of notes, so I've decided I need to improve the system as much as possible, with regard to all already existing texts. I've decided I will not validate/convert notes retroactively, because they were often so fragile that any automated conversion would blow them up. And it wasn't possible to be done manually, because there were simply too many of them.
An artificial example of how a typical note can look like, including unclosed tags and other errors:
<style>
.town-rules {
background-color: #88bb33;
padding: 30px;
}
</style>
<h1>Town rules!</h1>
<ol class="town-rules">
<li> no killing
<li> no whispering
</ol>
We are a nice town.
We like to trade.
<font color="red"><b>Please use these prices!</b></font>
<table>
<tr><td>Name</td><td>Value</td></tr>
<tr><td>Stone</td><td>30</td></tr>
<tr><td>Grapes</td><td>100</td>
</table>
My solution
The problem with embedding dangerous JavaScript begged for the proper solution - a whitelist of allowed tags and attributes, instead of blacklisting incorrect ones. After some research I found HTMLPurifier - an extensive PHP library for whitelist-based HTML validation with nice defaults. So the first step was easy, but I had to consider the already existing notes, which could be edited in the future. That's why I've decided to configure HTMLPurifier so it allows old 'Transitional HTML4'. People were also using things like display:none and so on, which was considered 'tricky' by HTMLPurifier, so these had to be allowed too. It sounds like I was almost done, but that was not so easy. Allowing HTML meant allowing people to style their notes, which means the use of CSS, both inline and as separate blocks in <style> tags. The HTMLPurifier config looks like this:
$config = HTMLPurifier_Config::createDefault();
$config->set('HTML.Doctype', 'HTML 4.01 Transitional');
$config->set('CSS.AllowTricky', true);
$config->set('CSS.Trusted', true);
$config->set('Attr.EnableID', true);
$config->set('Attr.DefaultImageAlt', "");
$config->set('Cache.SerializerPath', _ROOT_LOC . "/cache/HTMLPurifier");
Let's <pre> it all
There was also a funny quirk about notes rendering. To make it easier to use for people who just needed plaintext and didn't know how to make newlines in HTML, there was a special code in place: note's content displayed in the browser was encompassed by <pre></pre> tag (so 'normal' \n is displayed as a newline). In addition, to break too long lines (which were not auto-wrapped because of existence of <pre>), in the server-side rendering phase, the wordwrap PHP function was used. So it was a mix of special cases, which made the work much harder and the goal was to keep the system usable both for basic and advanced users.
As addition, because people knowing HTML didn't like builtin <pre> (because of newlines in random places) it was very common that the typical 'advanced' note structure looked like that:
</pre>
(Some text and HTML here)
<pre>
People were anticipating the existence of <pre> before the note's text and </pre> at the end, so they used that funny trick to disable it.
This special case was problematic in HTMLPurifier, because, normally, HTML doesn't allow any block-level tags in <pre>, so when I was trying to monkey-add it to the text before validation, then HTMLPurifier just stripped all the note contents. That was not acceptable, so I had to make a small hack, as in the code below:
/* The only two allowed situations are:
* 1. </pre> on the beginning and <pre> at the end of note
* 2. no occurrences of <pre> at all
* It's the only way to make HTMLPurifier work - it would
* remove any complicated tags nested in <pre> */
$hasPre = strstr($text, "</pre>");
$isPreTag = !empty($hasPre);
if ($isPreTag) {
$toClean = "<pre>" . $text . "</pre>";
} else {
$toClean = $text;
}
Then, after the cleaning, the temporary <pre>s from the beginning and the end are removed:
if ($isPreTag) {
$cleanHtml = substr($cleanHtml, 5, -6);
}
If there are any other <pre>s in the note text, then their content will most likely be stripped. But this is a rare case, so the solution is good enough to not have to come back to this issue.
What about CSS?
As I've said, styling is allowed both as inline CSS and in separate stylesheets. HTMLPurifier does allow and validate style attribute for inline styles, but it doesn't allow <style> tags, and, obviously, doesn't have any capabilities to validate its content. Fortunately, there's another library for that, which is called CSSTidy. It's not maintained for years, but it's working well, at least for the older CSS styles.
I had to integrate it with the note editing interface, considering the fact the <style> tags inserted by players are mixed with the HTML contents.
Some more code
CSSTidy constraints a few classes, including main csstidy class and csstidy_optimise helper class.
My class provides a slight modification of the original discard_invalid_selectors method which should validate whether the CSS selector is allowed, whose original implementation was basically a no-op. It's to disable most of advanced css modifiers, like :nth(3).
class CSSTidyOptimiseValidationExtension extends csstidy_optimise
{
public function __construct($css)
{
parent::__construct($css);
}
function discard_invalid_selectors(&$array)
{
foreach ($array as $selector => $decls) {
$ok = true;
$selectors = array_map('trim', explode(',', $selector));
foreach ($selectors as $s) {
$simple_selectors = preg_split('/\s*[+>~\s]\s*/', $s);
foreach ($simple_selectors as $ss) {
if ($ss === '') {
$ok = false;
} elseif (!preg_match("/^[a-zA-Z#\.][a-zA-Z0-9\-_\.#:]*$/", $ss)) {
$ok = false;
}
// could also check $ss for internal structure,
// but that probably would be too slow
}
}
if (!$ok) {
unset($array[$selector]);
}
}
}
}
But there comes the surprise from the creators of CSSTidy. The instance of csstidy_optimise is kept in a (public) field optimise of csstidy object, so it should be easy to replace, but then...
public function parse($string) {
...
// PHP bug? Settings need to be refreshed in PHP4
$this->print = new csstidy_print($this);
$this->optimise = new csstidy_optimise($this);
...the optimise field is re-assigned with the original implementation during the execution of the parse method o_O
It looks pretty weird and hard to bypass. I didn't want to alter the original code, so I had to make a small trick by using two PHP magic methods:
class MyCSSTidy extends csstidy
{
private $optimiseHolder;
public function __construct()
{
parent::__construct();
unset($this->optimise);
}
public function __set($property, $value)
{
if ($property == "optimise") {
// field "optimise" should never be assigned, to keep __get working
$this->optimiseHolder = new CSSTidyOptimiseValidationExtension($this);
} else {
$this->$property = $value;
}
}
public function __get($property)
{
if ($property == "optimise") {
return $this->optimiseHolder;
}
return null;
}
}
Why is it necessary to unset the original field? That's because of how __get works in PHP. Unlike Python, for example, __get method is called only when the property you want to retrieve doesn't exist. So it's meant only for a kind of fallback scenario. I had to remove the field created by the parent constructor and implement a __set method (which is called always when one tries to assign a variable) to make sure optimise field is never set and always results in call to __get.
Was it worth effort? Probably not, but this way the library can stay unchanged.
Visualization of HTMLPurifier's changes
I've managed to handle the situation when HTML&CSS needs to be checked and, if anything is wrong, automatically converted to the valid format. But in such scenario a typo in an opening tag could lead to the whole section of the original note being removed. Thus it was necessary to provide a preview of the note, so user is able to notice the problem and correct it before the text is saved.
Displaying the rendered version of the specified text was very easy - that's the same as when one wants to view the contents. But it is just enough to show that something is broken, and we want to know what exactly needs to be fixed. As a result, I've decided to show a diff between the original (user-specified) and the purified version.
Diff is a well-known way of displaying what has changed in the code. It looks like that:
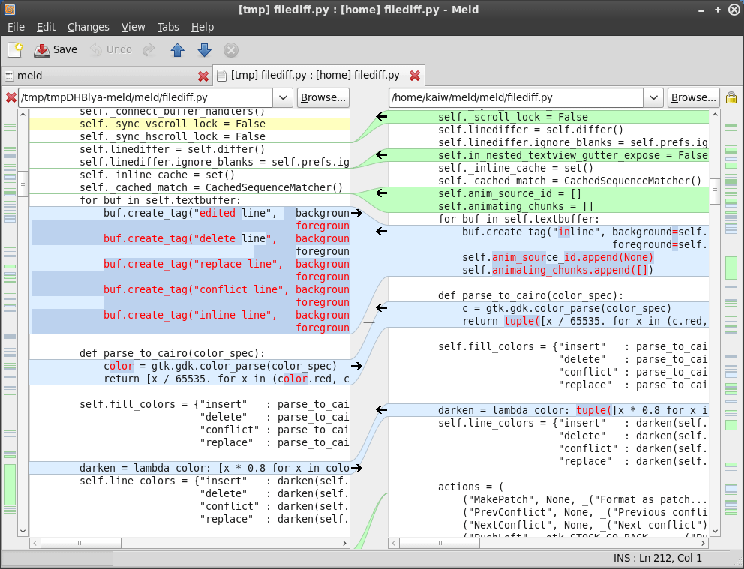
Diff presents changes between the old (left) and the new (right) version of the file
Majority of the diff libraries support line-level diff. If anything in a line is changed, then the whole line is marked as a change. I wanted a more fine-grained approach: character-level diff. One of such libraries is Google's DiffMatchPatch which is available in multiple languages. Unfortunately all options coded in PHP proved to be far too slow for long and HTML-heavy notes (taking as long as 10 minutes). So I've decided to use a version in Java, the more performant language I know pretty well.
All I had to do was to create a simple way of inter-process communication using stdin/stdout and running a separate Java process from PHP:
$pipeSpec = array( // both-sides communication
array("pipe", "r"),
array("pipe", "w"),
);
$pipes = array();
$env = array("JAVA_TOOL_OPTIONS" => "-Dfile.encoding=UTF-8");
$proc = proc_open("java -jar DiffMatchPatch/bin/notes-diff.jar",
$pipeSpec, $pipes, null, $env);
$in = $pipes[0];
$out = $pipes[1];
Nowadays I should probably create a HTTP-based microservice, but it was done a few years ago and it works well for the game with not so many users.
Presentation
The picture below looks similar as in the real game:
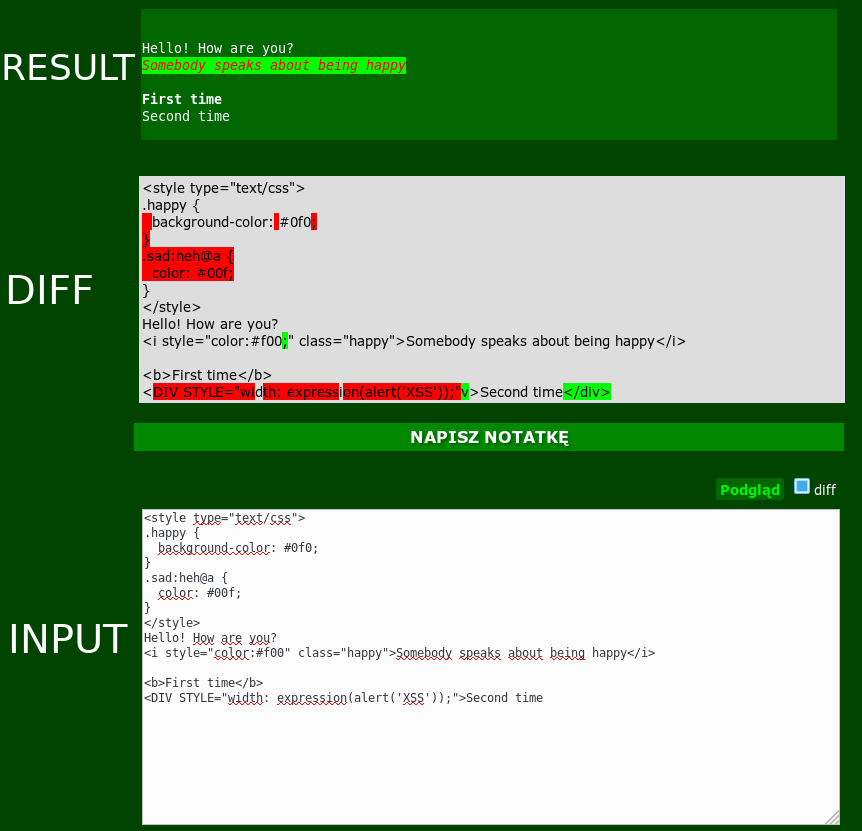
So you can type the input, see the rendered HTML version of it and also see the diff of changes done by the validator before you accept them and save the final version. (everything in Cantr is upside-down)
Summary
I don't know if it was an optimal solution, but, after years of functioning, so far it proved to be successful: people were able to modify their existing notes and create new ones, I also didn't get a single report about injecting the malicious code into the note contents. Maybe that's because the game is very niche, but even if so, then I find the solution good enough.